github에서 어두운 테마 설치
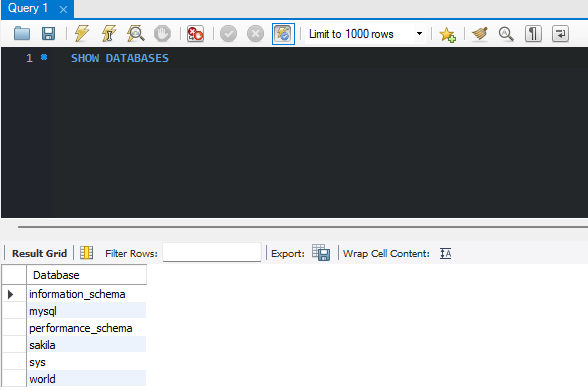
데이터베이스 모델링
테이블의 구조를 미리 설계하는 개념
현실 세계에 사용되는 작업이나 사물들을 DBMS의 테이블로 옮기기 위한 과정
개념적 데이터 모델 설계
논리적 데이터 모델 설계
물리적 데이터 모델 설계
폭포수 모델
소프트웨어 개발 단계 중 하나
폭포가 떨어지듯 개발 단계가 진행
계획 -> 요구사항 분석 -> 설계 -> 구현 -> 테스트 -> 유지보수
ㄴ문제가 발생할 경우 다시 앞 단계로 돌아가기 어려움
프로젝트
현실 세계에서 일어나는 업무를 컴퓨터 시스템으로 옮겨놓는 과정
대규모 소프트웨어를 작성하기 위한 전체 과정
데이터베이스 구성도
데이터: 하나하나의 단편적인 정보
테이블: 데이터를 입력하기 위해 표 형태로 표현한 것
데이터베이스: 테이블이 저장되는 저장소
DBMS: 데이터베이스 관리 시스템 또는 소포트웨어
열: 테이블 세로, 테이블은 여러 열로 구성
열 이름: 각 열을 구분하기 위한 이름
데이터 형식: 열에 저장될 데이터 형식
행: 테이블의 가로, 실질적 데이터
기본키: 각 행을 구분하는 유일한 열
SQL: DBMS에서 작업을 하기 위해 필요한 구조화된 질의 언어


데이터베이스
데이터 저장하는 공간
데이터베이스 구축 절차
데이터베이스 만들기 -> 테이블 만들기 -> 데이터 입력/수정/삭제하기 -> 데이터 조회/활용하기
테이블 만들기



데이터 입력하기
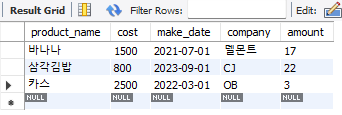
데이터 활용하기
SELECT 기본 형식
SELECT 열_이름 FROM 테이블_이름[WHERE 조건]

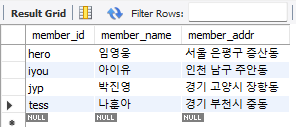
SELECT member_name, member_addr FROM member;
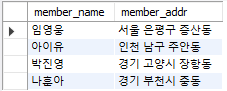
마우스로 드래그해서 선택 실행
SELECT member_name, member_addr FROM member;
SELECT * FROM member WHERE member_name = '아이유';

스키마: MySQL 안의 데이터 베이스
데이터 형식: CHAR, INT 등
예약어: SELECT, FROM, WHERE 같은 기존에 약속된 SQL
기본키: 열에 지정, 각 행을 구분하는 유일한 값
인텔리센스: SQL의 글자가 미리 제시되는 워크벤치 기능
데이터베이스 개체
인덱스: 책 뒤 '찾아보기'와 비슷한 개념, 데이터 빠르게 찾게 도와줌
뷰: '바로가기 아이콘'과 비슷한 개념, '가상의 테이블'
스토어드 프로시저: 여러 개의 SQL을 묶어주거나, 프로그래밍 기능 제공
| 한글 | 영어 | 설명 |
| 데이터베이스 개체 | Database Object | 테이블, 뷰, 인덱스, 스토어드 프로시저 등 데이터베이스 안에 저장되는 개체 |
| 실행 계획 | Execution Plan | SQL을 실행할 때, 인덱스 사용 여부를 확인할 수 있는 워크벤치 화면 |
| 전체 테이블 검색 | Full Table Scan | 테이블의 모든 데이터를 훑어 원하는 데이터를 찾아내는 것, 책 전체 찾아보기와 비슷 |
| 인덱스 검색 | Index Scan | 인덱스를 통해 데이터를 찾는 것을 말함, 책 뒤 찾아보기를 사용하는 것과 비슷 |
| 구분 문자 | DELIMITER | 스토어드 프로시저를 묶어주는 예약어 |
| 호출 | CALL | 스토어드 프로시저를 호출하는 예약어 |
| 개체 생성문 | CREATE | 데이터베이스 개체를 생성할 때 사용하는 예약어 |
| 개체 삭제문 | DROP | 데이터베이스 개체를 삭제할 때 사용하는 예약어 |
인덱스 실습
SELECT * FROM member WHERE member_name = '아이유';

전체 테이블 검색

CREATE INDEX idx_member_name ON member(member_name);
SELECT * FROM member WHERE member_name = '아이유';

SQL 기본 문법
SELECT문: 구축이 완료된 테이블에서 데이터 추출하는 기능
https://www.hanbit.co.kr/support/supplement_survey.html?pcode=B6846155853
한빛+
사람을 잇고 지식과 경험을 엮어 세상을 바꾸는 디지털 콘텐츠 기업
www.hanbit.co.kr
실습용 데이터베이스 구축
DROP DATABASE IF EXISTS market_db; -- 만약 market_db가 존재하면 우선 삭제한다.
CREATE DATABASE market_db;
USE market_db;
CREATE TABLE member -- 회원 테이블
( mem_id CHAR(8) NOT NULL PRIMARY KEY, -- 사용자 아이디(PK)
mem_name VARCHAR(10) NOT NULL, -- 이름
mem_number INT NOT NULL, -- 인원수
addr CHAR(2) NOT NULL, -- 지역(경기,서울,경남 식으로 2글자만입력)
phone1 CHAR(3), -- 연락처의 국번(02, 031, 055 등)
phone2 CHAR(8), -- 연락처의 나머지 전화번호(하이픈제외)
height SMALLINT, -- 평균 키
debut_date DATE -- 데뷔 일자
);
CREATE TABLE buy -- 구매 테이블
( num INT AUTO_INCREMENT NOT NULL PRIMARY KEY, -- 순번(PK)
mem_id CHAR(8) NOT NULL, -- 아이디(FK)
prod_name CHAR(6) NOT NULL, -- 제품이름
group_name CHAR(4) , -- 분류
price INT NOT NULL, -- 가격
amount SMALLINT NOT NULL, -- 수량
FOREIGN KEY (mem_id) REFERENCES member(mem_id)
);
INSERT INTO member VALUES('TWC', '트와이스', 9, '서울', '02', '11111111', 167, '2015.10.19');
INSERT INTO member VALUES('BLK', '블랙핑크', 4, '경남', '055', '22222222', 163, '2016.08.08');
INSERT INTO member VALUES('WMN', '여자친구', 6, '경기', '031', '33333333', 166, '2015.01.15');
INSERT INTO member VALUES('OMY', '오마이걸', 7, '서울', NULL, NULL, 160, '2015.04.21');
INSERT INTO member VALUES('GRL', '소녀시대', 8, '서울', '02', '44444444', 168, '2007.08.02');
INSERT INTO member VALUES('ITZ', '잇지', 5, '경남', NULL, NULL, 167, '2019.02.12');
INSERT INTO member VALUES('RED', '레드벨벳', 4, '경북', '054', '55555555', 161, '2014.08.01');
INSERT INTO member VALUES('APN', '에이핑크', 6, '경기', '031', '77777777', 164, '2011.02.10');
INSERT INTO member VALUES('SPC', '우주소녀', 13, '서울', '02', '88888888', 162, '2016.02.25');
INSERT INTO member VALUES('MMU', '마마무', 4, '전남', '061', '99999999', 165, '2014.06.19');
INSERT INTO buy VALUES(NULL, 'BLK', '지갑', NULL, 30, 2);
INSERT INTO buy VALUES(NULL, 'BLK', '맥북프로', '디지털', 1000, 1);
INSERT INTO buy VALUES(NULL, 'APN', '아이폰', '디지털', 200, 1);
INSERT INTO buy VALUES(NULL, 'MMU', '아이폰', '디지털', 200, 5);
INSERT INTO buy VALUES(NULL, 'BLK', '청바지', '패션', 50, 3);
INSERT INTO buy VALUES(NULL, 'MMU', '에어팟', '디지털', 80, 10);
INSERT INTO buy VALUES(NULL, 'GRL', '혼공SQL', '서적', 15, 5);
INSERT INTO buy VALUES(NULL, 'APN', '혼공SQL', '서적', 15, 2);
INSERT INTO buy VALUES(NULL, 'APN', '청바지', '패션', 50, 1);
INSERT INTO buy VALUES(NULL, 'MMU', '지갑', NULL, 30, 1);
INSERT INTO buy VALUES(NULL, 'APN', '혼공SQL', '서적', 15, 1);
INSERT INTO buy VALUES(NULL, 'MMU', '지갑', NULL, 30, 4);
SELECT * FROM member;
SELECT * FROM buy;
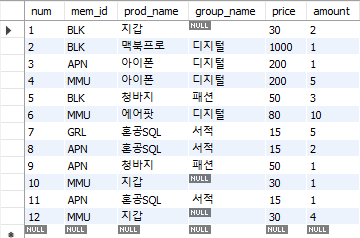
AUTO_INCREMENT: 자동으로 숫자 입력
USE문: 데이터베이스를 선택하는 구문
관계 연산자: WHERE절에서 지정하는 기호 <, <=, >, >=, = 등
논리 연산자: AND, OR, NOT 등...TF
LIKE: 문자열 비교시 모두 허용일 땐 %, 하나만일 때는 _
SELECT * FROM market_db.member;
필요한 열만
SELECT mem_name FROM member;
SELECT addr, mem_name FROM member;
별칭 만들기
SELECT addr 주소, debut_date "데뷔 일자", mem_name FROM member;

기본적인 WHERE 절
SELECT 열_이름 FROM 테이블_이름 WHERE 조건식;
SELECT * FROM member WHERE mem_number = 4;

관계 연산자, 논리 연산자 사용
SELECT mem_name, mem_number FROM member WHERE height >= 165 AND mem_number > 6;

BETWEEN ~ AND
SELECT mem_name, height FROM member WHERE height >= 163 AND height < 165;
IN()
SELECT mem_name, addr FROM member WHERE addr IN('경기', '전남', '경남');
LIKE
문자열 비교 시 모두 허용은 %, 하나로 지정할 땐 _
SELECT * FROM member WHERE mem_name LIKE '우%';
SELECT * FROM member WHERE mem_name LIKE '__핑크';
서브쿼리
SELECT 안에 SELECT
SELECT mem_name, height FROM member WHERE height > (SELECT height FROM member WHERE mem_name = '에이핑크');
SELECT문
ORDER BY: 결과의 정렬
LIMIT: 결과의 개수 제한
DISTINCT: 중복 데이터 제거
GROUP BY절: 지정한 열의 데이터들을 같은 데이터끼리 묶어 결과 추출
HAVING절: GROUP BY절과 함께 사용됨
ORDER BY절: 결과의 값이나 개수에 대해서 영향X, 결과가 출력되는 순서 조절
ㄴASC 오름차순
ㄴDESC 내림차순
SELECT mem_id, mem_name, debut_date FROM member ORDER BY debut_date;

WHERE절과 함께 사용
SELECT mem_id, mem_name, debut_date FROM member WHERE height >= 164 ORDER BY height DESC;
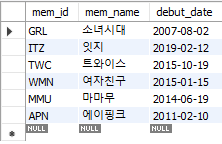
SELECT mem_id, mem_name, debut_date, height FROM member WHERE height >= 164 ORDER BY height DESC, debut_date ASC;

LIMIT: 출력 개수 제한
LIMIT 시작, 개수 형식
SELECT mem_name, height FROM member ORDER BY height DESC LIMIT 3, 2;
평균키 큰 순으로 정렬 + 3번째부터 2건만
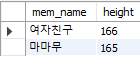
DISTINCT: 중복 결과 제거
SELECT DISTINCT addr FROM member;

GROUP BY절: 그룹을 묶어주는 역할
데이터 그룹화 기능
집계 함수: GROUP BY와 함께 사용됨
ㄴ SUM(), AVG(), MIN(), MAX(), COUNT(), COUNT(DISTINCT)
SELECT mem_id, SUM(amount) FROM buy GROUP BY mem_id;

SELECT mem_id "회원 아이디", SUM(price*amount) "총 구매 금액" FROM buy GROUP BY mem_id;
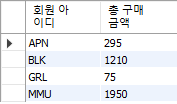
COUNT(*)는 모든 행의 개수를 세고, COUNT(열_이름)은 열 이름의 값이 NULL인 것을 제외한 행의 개수를 셈
Having절: WHERE과 비슷한 개념, 집계 함수에 대해 조건을 제한하는 것
ㄴ GROUP BY 절 다음에 나와야 함
SELECT mem_id "회원 아이디", SUM(price*amount) "총 구매 금액" FROM buy GROUP BY mem_id HAVING SUM(price*amount) > 1000 ORDER BY SUM(price*amount) DESC;

데이터 변경을 위한 SQL문
INSERT: 입력
UPDATE: 수정
DELETE: 삭제
INSERT문
INSERT INTO 테이블 [(열1, 열2, ...)] VALUES (값1, 값2, ...)
USE market_db;
CREATE TABLE hongong1 (toy_id INT, toy_name CHAR(4), age INT);
INSERT INTO hongong1 VALUES (1, '우디', 25);
select * from hongong1;

USE market_db;
CREATE TABLE IF NOT EXISTS hongong1 (toy_id INT, toy_name CHAR(4), age INT);
INSERT INTO hongong1 VALUES (1, '우디', 25);
INSERT INTO hongong1 (toy_id, toy_name) VALUES (2, '버즈');
INSERT INTO hongong1 (toy_name, age, toy_id) VALUES ('제시', 20, 3);
select * from hongong1;
AUTO_INCREMENT: 자동 증가
CREATE TABLE hongong2 (
toy_id INT AUTO_INCREMENT PRIMARY KEY,
toy_name CHAR(4),
age INT);
INSERT INTO hongong2 VALUES (NULL, '보핍', 25);
INSERT INTO hongong2 VALUES (NULL, '슬링키', 22);
INSERT INTO hongong2 VALUES (NULL, '렉스', 21);
SELECT * FROM hongong2;
SELECT LAST_INSERT_ID();

ALTER TABLE HONGONG2 AUTO_INCREMENT=100;
INSERT INTO hongong2 VALUES (NULL, '재남', 35);
SELECT * FROM hongong2;

시스템 변수: MySQL에서 자체적으로 가지고 있는 설정값이 저장된 변수
ㄴSELECT @@시스템변수
여러 줄을 한줄로 작성
drop table if exists hongong2;
CREATE TABLE hongong2 (
toy_id INT AUTO_INCREMENT PRIMARY KEY,
toy_name CHAR(4),
age INT);
INSERT INTO hongong2 VALUES (NULL, '보핍', 25), (NULL, '슬링키', 22), (NULL, '렉스', 21);
SELECT * FROM hongong2;
SELECT LAST_INSERT_ID();
ALTER TABLE HONGONG2 AUTO_INCREMENT=100;
INSERT INTO hongong2 VALUES (NULL, '재남', 35);
SELECT * FROM hongong2;
다른 테이블 데이터 한번에 입력하는 INSERT INTO ~ SELECT
SELECT COUNT(*)city FROM world.city;
DESC world.city;

CRUD 구성 요소
Create생성
Read읽기
Update갱신
Delete삭제
UPDATE: 데이터 수정
USE world;
update city_popul set city_name='서울' where city_name='Seoul';
Select * from city_popul where city_name ='서울';
USE world;
update city_popul set city_name='뉴욕', populatin=0 where city_name='New York';
Select population from city_popul where city_name ='뉴욕';
UPdate city_popul
SET city_name = '뉴욕', population = 0
WHERE city_name = 'New York';
SELECT * FROM city_popul WHERE city_name = '뉴욕';
DELETE: 데이터 삭제(행 단위, WHERE 없으면 전체 행)
DELETE FROM city_popul
WHERE city_name LIKE 'New%';
대용량 테이블의 삭제
CREATE TABLE big_table1 (SELECT * FROM world.city, sakila.country);
CREATE TABLE big_table2 (SELECT * FROM world.city, sakila.country);
CREATE TABLE big_table3 (SELECT * FROM world.city, sakila.country);
SELECT COUNT(*) FROM big_table1;
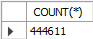
DELETE FROM big_table1;
DROP TABLE big_table2;
TRUNCATE TABLE big_table3;
| 3 | 36 | 15:13:16 | DELETE FROM big_table1 | 444611 row(s) affected | 2.922 sec |
| 3 | 37 | 15:13:19 | DROP TABLE big_table2 | 0 row(s) affected | 0.062 sec |
| 3 | 38 | 15:13:19 | TRUNCATE TABLE big_table3 | 0 row(s) affected | 0.094 sec |
SQL 고급 문법
데이터 형식
정수형
TINYINT: 1바이트, -128~127
SMALLINT: 2바이트,-32768~32767
INT: 4바이트, 약-21억~21억
BIGINT: 8바이트, 약-900경~900경
USE market_db;
CREATE TABLE hongong4 (
tinyint_col TINYINT,
smallint_col SMALLINT,
int_col INT,
bigint_col BIGINT);
select * from hongong4;
desc hongong4;

INSERT INTO hongong4 VALUES(127, 32767, 2147483647, 9000000000000000000);
INSERT INTO hongong4 VALUES(128, 32768, 2147483648, 90000000000000000000);
| 3 | 46 | 15:36:32 | INSERT INTO hongong4 VALUES(127, 32767, 2147483647, 9000000000000000000) | 1 row(s) affected | 0.015 sec |
| 0 | 47 | 15:36:32 | INSERT INTO hongong4 VALUES(128, 32768, 2147483648, 90000000000000000000) | Error Code: 1264. Out of range value for column 'tinyint_col' at row 1 | 0.000 sec |
정수형에 UNSIGNED를 붙이면 범위가 0부터 지정됨
TINYINT: -128 ~127
TINYINT UNSIGNED: 0 ~ 255
CHAR: 문자형
CHAR(개수): 1~255
VARCHAR(개수): 1~16383
CHAR는 글자 개수가 고정된 경우, VARCHAR는 글자 개수가 변동될 경우에 사용하는 것이 좋음
대량의 데이터 형식
TEXT 형식
ㄴTEXT: 1~65535
ㄴLONGTEXT: 1~4294967295
BLOB 형식
ㄴBLOB: 1~65535
ㄴLONGBLOB: 1~4294967295
자막은 LONG TEXT, 동영상은 LONGBLOB로 설정해야 대용량 텍스트와 이진 데이터 저장 가능
실수형
FLOAT: 4, 소수점 아래 7자리까지 표현
DOUBLE: 8, 소수점 아래 15자리까지 표현
날짜형
DATE: 3, 날짜만 저장. YYYY-MM-DD형식
TIME: 3, 시간만 저장. HH:MM:SS 형식
DATETIME: 8, 날짜 및 시간 저장 YYYY-MM-DD HH:MM:SS 형식
변수 사용
변수 앞에는 @ 붙임
SET @변수이름 = 변수 값;
SELECT @변수이름;
USE market_db;
SET @myVar1 = 5;
SET @myVar2 = 4.25;
SELECT @myVar1;
SELECT @myVar1 + @myVar2;
SET @txt = '가수 이름==>';
SET @height = 166;
SELECT @txt, mem_name FROM member WHERE height > @height;
PREPARE, EXECUTE 사용(LIMIT에선 변수 사용 X)
SET @count = 3;
PREPARE mySQL FROM 'SELECT mem_name, height FROM member ORDER BY height LIMIT ?';
EXECUTE mySQL USING @count;

데이터 형 변환: 문자형을 정수형으로 바꾸거나, 반대로 정수형을 문자형으로 바꾸는 것
명시적인 변환: 직접 함수를 사용해서 변환
암시적인 변환: 별도 지시 없이 자연스럽게 변환
함수를 이용한 명시적 변환
CAST ( 값 AS 데이터_형식 [ (길이) ] )
CONVERT ( 값, 데이터_형식 [ (길이) ] )
SELECT AVG(price) AS '평균 가격' FROM buy;

SELECT CAST(AVG(price) AS SIGNED) '평균 가격' FROM buy;

SELECT num, CONCAT(CAST(price AS CHAR), 'X', CAST(amount AS CHAR), '=')
'가격x수량', price*amount '구매액'
FROM buy;
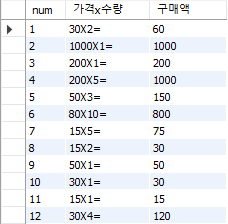
숫자와 문자를 연산할 때 CONCAT()을 사용하면 숫자가 문자로 변하고, 더하기만 사용하면 문자가 숫자로 변한 후 연산
조인(내부 조인)
두 테이블을 엮어서 정보를 추출하는 것
두 테이블의 조인을 위해 기본키-외래 키 관계로 맺어져야 하고, 이를 '일대다 관계'라고 부름
내부 조인의 형식
SELECT <열 목록>
FROM <첫 번째 테이블>
INNER JOIN <두 번째 테이블> -- INNER JOIN을 그냥 JOIN으로 써도 인식
ON <조인될 조건>
[WHERE 검색 조건]
USE market_db;
SELECT * FROM buy INNER JOIN member ON buy.mem_id = member.mem_id WHERE buy.mem_id = 'GRL';

USE market_db;
SELECT * FROM buy INNER JOIN member ON buy.mem_id = member.mem_id;

SELECT buy.mem_id, member.mem_name, buy.prod_name, member.addr, CONCAT(member.phone1, member.phone2) '연락처' FROM buy INNER JOIN member On buy.mem_id = member.mem_id;

SELECT M.mem_id, M.mem_name, B.prod_name, M.addr
FROM buy B
INNER JOIN member M
ON B.mem_id = M.mem_id
ORDER BY M.mem_id;

내부 조인은 두 테이블에 모두 있는 내용만 출력
중복된 결과 1개만 출력하기(DISTINCT)
SELECT DISTINCT M.mem_id, M.mem_name, M.addr
FROM buy B
INNER JOIN member M
ON B.mem_id = M.mem_id
ORDER BY M.mem_id;
외부 조인
두 테이블을 조인할 때 필요한 내용이 한쪽 테이블에만 있어도 결과 추출 가능, 자주 사용 X
SELECT <열 목록>
FROM <첫 번째 테이블(LEFT 테이블)>
<LEFT | RIGHT | FULL> OUTER JOIN <두 번째 테이블(RIGHT 테이블)>
ON <조인될 조건>
[WHERE 검색 조건];
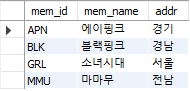
SELECT M.mem_id, M.mem_name, B.prod_name, M.addr
FROM member M
LEFT OUTER JOIN buy B
ON M.mem_id = B.mem_id
ORDER BY M.mem_id;
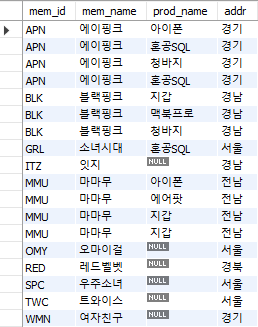
SELECT M.mem_id, M.mem_name, B.prod_name, M.addr
FROM buy B
RIGHT OUTER JOIN member M
ON M.mem_id = B.mem_id
ORDER BY M.mem_id;

외부 조인 활용
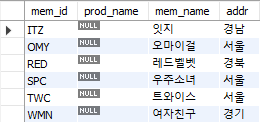
SELECT DISTINCT M.mem_id, B.prod_name, M.mem_name, M.addr
FROM member M
LEFT OUTER JOIN buy B
ON M.mem_id = B.mem_id
WHERE B.prod_name IS NULL
ORDER BY M.mem_id;
기타 조인-가끔 사용되는 상호조인과 자체 조인
상호조인
한쪽 테이블의 모든 행과 다른 쪽 테이블의 모든 행을 조인시키는 기능
ON 구문 사용 X
결과의 내용 의미X, 랜덤 조인
상호 조인의 주 용도는 테스트하기 위해 대용량의 데이터를 생성할 때
SELECT * FROM buy CROSS JOIN member;

대용량 테이블을 만들 때: CREATE TABLE ~ SELECT
CREATE TABLE cross_table
SELECT *
FROM sakila.actor
CROSS JOIN world.country;
SELECT * FROM cross_table LIMIT 5;

자체 조인
자신과 조인
SELECT <열 목록>
FROM <테이블> 별칭A
INNER JOIN <테이블> 별칭B
ON <조인될 조건>
[WHERE 검색 조건]
'로보테크AI' 카테고리의 다른 글
| 융합_로보테크 AI 자율주행 로봇 개발자 과정-26/01/23[TCP] (1) | 2026.01.23 |
|---|---|
| 융합_로보테크 AI 자율주행 로봇 개발자 과정-26/01/22 (0) | 2026.01.22 |
| 융합_로보테크 AI 자율주행 로봇 개발자 과정-26/01/20[SQL] (1) | 2026.01.20 |
| 융합_로보테크 AI 자율주행 로봇 개발자 과정-26/01/19 (0) | 2026.01.19 |
| 융합_로보테크 AI 자율주행 로봇 개발자 과정-26/01/15 (0) | 2026.01.15 |