인공지능
사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템을 만드는 기술
머신러닝
규칙을 일일히 프로그래밍하지 않아도 자동으로 데이터에서 규칙을 학습하는 알고리즘
다량의 데이터를 통해 패턴을 찾아내고 결과를 추론하는 알고리즘
학습: 데이터 입력
추론: 헉숩 데이터 토대로 결과 출력
딥러닝
머신러닝 알고리즘 중 인공 신경망 기반인 방법을 통칭
ㄴTensorFlow, PyTorch
머신러닝, 딥러닝 공부 =/= 알고리즘 개발(통계학, 수학, 과학)
머신러닝, 딥러닝을 이용한 개발 학습(API)
Google Colab으로 진행

## 마크다운으로 작성하는 텍스트 셀
# 마크다운 전체 문법 정리
## 1. 제목 (Heading)
| 문법 | 결과 | 비고 |
|:-----|:-----|:-----|
| `# 텍스트` | H1 (가장 큰 제목) | `#` 1~6개 사용 가능 |
| `## 텍스트` | H2 | |
| `### 텍스트` | H3 | |
| `#### 텍스트` | H4 | |
| `##### 텍스트` | H5 | |
| `###### 텍스트` | H6 (가장 작은 제목) | |
---
## 2. 텍스트 강조
| 문법 | 결과 | 비고 |
|:-----|:-----|:-----|
| `**텍스트**` | **굵게** | Bold |
| `*텍스트*` | *기울임* | Italic |
| `***텍스트***` | ***굵게+기울임*** | Bold + Italic |
| `~~텍스트~~` | ~~취소선~~ | Strikethrough |
| `<u>텍스트</u>` | <u>밑줄</u> | HTML 태그 사용 |
---
## 3. 목록 (List)
| 종류 | 문법 | 비고 |
|:-----|:-----|:-----|
| 순서 없는 목록 | `- 항목` 또는 `* 항목` | `-`, `*`, `+` 모두 가능 |
| 순서 있는 목록 | `1. 항목` | 숫자는 자동 증가 |
| 중첩 목록 | 앞에 공백 2~4칸 들여쓰기 | 탭(Tab) 사용 가능 |
| 체크박스 | `- [ ] 항목` / `- [x] 항목` | GitHub, Colab 지원 |
---
## 4. 링크 & 이미지
| 종류 | 문법 | 비고 |
|:-----|:-----|:-----|
| 링크 | `[텍스트](URL)` | 클릭 가능한 링크 |
| 링크 (툴팁) | `[텍스트](URL "설명")` | 마우스 올리면 설명 표시 |
| 이미지 | `` | `!`를 앞에 붙임 |
| 이미지 (툴팁) | `` | |
---
## 5. 코드
| 종류 | 문법 | 비고 |
|:-----|:-----|:-----|
| 인라인 코드 | `` `코드` `` | 백틱 1개로 감싸기 |
| 코드 블록 | ` ``` ` 로 위아래 감싸기 | 백틱 3개 |
| 언어 지정 | ` ```python ` 처럼 언어명 명시 | 문법 강조(Syntax Highlight) 적용 |
---
## 6. 인용문 (Blockquote)
| 문법 | 비고 |
|:-----|:-----|
| `> 텍스트` | 인용 블록 생성 |
| `>> 텍스트` | 중첩 인용 |
| `> **굵게** 도 가능` | 내부에 다른 문법 중첩 가능 |
---
## 7. 구분선 (Horizontal Rule)
| 문법 | 비고 |
|:-----|:-----|
| `---` | 수평선 생성 |
| `***` | 동일 결과 |
| `___` | 동일 결과 |
---
## 8. 표 (Table)
| 문법 | 비고 |
|:-----|:-----|
| `\| 헤더 \| 헤더 \|` | 헤더 행 |
| `\|---\|---\|` | 구분선 행 (필수) |
| `\| 내용 \| 내용 \|` | 데이터 행 |
| `\|:---\|` | 왼쪽 정렬 |
| `\|---:\|` | 오른쪽 정렬 |
| `\|:---:\|` | 가운데 정렬 |
---
## 9. 기타
| 종류 | 문법 | 비고 |
|:-----|:-----|:-----|
| 줄바꿈 | 문장 끝에 공백 2칸 + Enter | 또는 `<br>` |
| 단락 구분 | 빈 줄 1개 삽입 | Enter 2번 |
| 이스케이프 | `\*`, `\#`, `\|` 등 | 특수문자 앞에 `\` |
| HTML 태그 | `<b>`, `<br>`, `<u>` 등 | 대부분의 마크다운에서 지원 |
| 각주 | `텍스트[^1]` + `[^1]: 설명` | GitHub, Notion 등 지원 |
이진 분류
분류: 머신러닝에서 여러 개의 종류(클래스) 중 하나를 구별해 내는 문제
2개의 클래스 중 하나를 고르는 문제
데이터
도미, 빙어 구분
무게, 길이 제공
무게, 길이에 따른 분류 방법
도미의 무게와 길이, 빙어의 무게와 길이 각각 제공
이때 무게와 길이는 피쳐(특성)이라 함
학습하기 전 데이터 시각화로 데이터 양상 파악
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]
특성: 데이터 특징
산점도: x, y축으로 이뤄진 좌표계에서 두 변수(x, y)의 관계를 표현하는 방법
matplotlib: 파이썬에서 과학계산용 그래프 그리는 패키지
import: 파이썬 패캐지를 사용하기 위해 불러오는 명령
import matplotlib.pyplot as plt
plt.scatter(bream_length, bream_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
빙어 데이터 준비
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
시각화
plt.scatter(bream_length, bream_weight)
plt.scatter(smelt_length, smelt_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
k-최근접 이웃 알고리즘
어떤 샘플에 대해 추론할 때 가장 가까운 기준을 토대로 판단
리스트 하나로 통합하기
length = bream_length + smelt_length
weight = bream_weight + smelt_weight
사이킷런
머신러닝 패키지
ㄴ리스트 내포로 2차원 리스트로 정렬
ㄴzip(): 나열된 리스트에서 원소를 하나씩 꺼내주는 역할
fish_data = [[l, w] for l, w in zip(length, weight)]
print(fish_data)
#[[25.4, 242.0], [26.3, 290.0], [26.5, 340.0], [29.0, 363.0], [29.0, 430.0], [29.7, 450.0], [29.7, 500.0], [30.0, 390.0], [30.0, 450.0], [30.7, 500.0], [31.0, 475.0], [31.0, 500.0], [31.5, 500.0], [32.0, 340.0], [32.0, 600.0], [32.0, 600.0], [33.0, 700.0], [33.0, 700.0], [33.5, 610.0], [33.5, 650.0], [34.0, 575.0], [34.0, 685.0], [34.5, 620.0], [35.0, 680.0], [35.0, 700.0], [35.0, 725.0], [35.0, 720.0], [36.0, 714.0], [36.0, 850.0], [37.0, 1000.0], [38.5, 920.0], [38.5, 955.0], [39.5, 925.0], [41.0, 975.0], [41.0, 950.0], [9.8, 6.7], [10.5, 7.5], [10.6, 7.0], [11.0, 9.7], [11.2, 9.8], [11.3, 8.7], [11.8, 10.0], [11.8, 9.9], [12.0, 9.8], [12.2, 12.2], [12.4, 13.4], [13.0, 12.2], [14.3, 19.7], [15.0, 19.9]]
도미와 빙어를 분류하기 위해 하는 작업 순서
<데이터 전처리>
1. 데이터 준비(리스트)
2. 시각화(데이터 양상 확인)
<학습>
3. 데이터(특성)와 그 데이터가 무엇인지(종류)에 대한 정보
ㄴ길이와 무게를 리스트로 묶어서 표현했고,
ㄴ도미와 빙어를 1과 0으로 구분해 표현
fish_target = [1] * 35 + [0] * 14
print(fish_target)
#[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
from sklearn.neighbors import KNeighborsClassifierkn = KNeighborsClassifier()
훈련 시키기 fit() 메서드
kn.fit(fish_data, fish_target)
사이킷런 모델 평가 score() 메서드
kn.score(fish_data, fish_target)
# 1.0
새로운 데이터 가정
plt.scatter(bream_length, bream_weight)
plt.scatter(smelt_length, smelt_weight)
plt.scatter(30, 600, marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()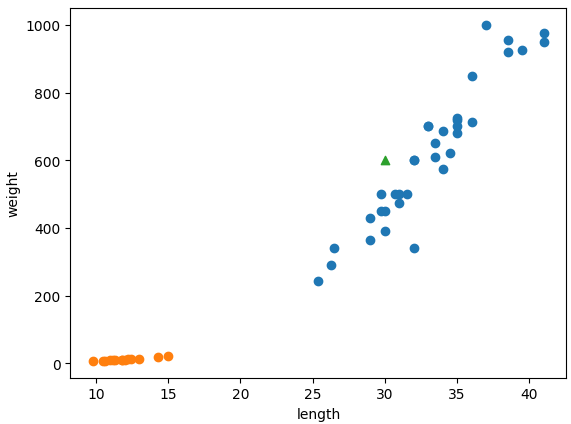
판단
kn.predict([[30, 600]])
# array([1])print(kn._fit_X)[[ 25.4 242. ]
[ 26.3 290. ]
[ 26.5 340. ]
[ 29. 363. ]
[ 29. 430. ]
[ 29.7 450. ]
[ 29.7 500. ]
[ 30. 390. ]
[ 30. 450. ]
[ 30.7 500. ]
[ 31. 475. ]
[ 31. 500. ]
[ 31.5 500. ]
[ 32. 340. ]
[ 32. 600. ]
[ 32. 600. ]
[ 33. 700. ]
[ 33. 700. ]
[ 33.5 610. ]
[ 33.5 650. ]
[ 34. 575. ]
[ 34. 685. ]
[ 34.5 620. ]
[ 35. 680. ]
[ 35. 700. ]
[ 35. 725. ]
[ 35. 720. ]
[ 36. 714. ]
[ 36. 850. ]
[ 37. 1000. ]
[ 38.5 920. ]
[ 38.5 955. ]
[ 39.5 925. ]
[ 41. 975. ]
[ 41. 950. ]
[ 9.8 6.7]
[ 10.5 7.5]
[ 10.6 7. ]
[ 11. 9.7]
[ 11.2 9.8]
[ 11.3 8.7]
[ 11.8 10. ]
[ 11.8 9.9]
[ 12. 9.8]
[ 12.2 12.2]
[ 12.4 13.4]
[ 13. 12.2]
[ 14.3 19.7]
[ 15. 19.9]]
k-최근접 이웃 알고리즘은 데이터가 많으면 불리
print(kn._y)
# [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0
# 0 0 0 0 0 0 0 0 0 0 0 0]
참고 데이터 49개로 제한
kn49 = KNeighborsClassifier(n_neighbors=49)kn49.fit(fish_data, fish_target)
kn49.score(fish_data, fish_target)
# 0.7142857142857143print(35/49)
# 0.7142857142857143
지도학습
입력(데이터)과 타깃(정답)으로 이뤄진 훈련 데이터가 필요
문제에 대한 답을 알려준 다음 새로운 문제를 푸는 것
비지도학습
답은 없고, 데이터만 있으니 패턴을 분석하여 문제를 푸는 것
훈련 데이터
입력: 문제(특성)
타깃: 정답
테스트 세트: 평가에 사용하는 데이터
훈련 세트: 훈련에 사용되는 데이터
ㄴ 테스트, 훈련 세트는 따로 준비
fish_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0, 9.8,
10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
fish_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0, 6.7,
7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]fish_data = [[l, w] for l, w in zip(fish_length, fish_weight)]
fish_target = [1]*35 + [0]*14
샘플: 하나의 데이터
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()
인덱스 지정
print(fish_data[4])
# [29.0, 430.0]
슬라이싱
인덱스의 범위 지정하여 원소 여러개 선택
print(fish_data[0:5])
# [[25.4, 242.0], [26.3, 290.0], [26.5, 340.0], [29.0, 363.0], [29.0, 430.0]]
print(fish_data[:5])
# [[25.4, 242.0], [26.3, 290.0], [26.5, 340.0], [29.0, 363.0], [29.0, 430.0]]
print(fish_data[44:])
# [[12.2, 12.2], [12.4, 13.4], [13.0, 12.2], [14.3, 19.7], [15.0, 19.9]]
훈련 데이터 선택
train_input = fish_data[:35]
train_target = fish_target[:35]
test_input = fish_data[35:]
test_target = fish_target[35:]
평가
kn.fit(train_input, train_target)
kn.score(test_input, test_target)
# 0.0
샘플링 편향
훈련, 테스트 세트에 샘플이 골고루 섞여있지 않아 한쪽으로 치우쳐짐
넘파이
파이썬 배열 라이브러리
import numpy as np
1차원: 선
2차원: 면
3차원: 공간
파이썬 리스트 array()함수에 전달
input_arr = np.array(fish_data)
target_arr = np.array(fish_target)print(input_arr)[[ 25.4 242. ]
[ 26.3 290. ]
[ 26.5 340. ]
[ 29. 363. ]
[ 29. 430. ]
[ 29.7 450. ]
[ 29.7 500. ]
[ 30. 390. ]
[ 30. 450. ]
[ 30.7 500. ]
[ 31. 475. ]
[ 31. 500. ]
[ 31.5 500. ]
[ 32. 340. ]
[ 32. 600. ]
[ 32. 600. ]
[ 33. 700. ]
[ 33. 700. ]
[ 33.5 610. ]
[ 33.5 650. ]
[ 34. 575. ]
[ 34. 685. ]
[ 34.5 620. ]
[ 35. 680. ]
[ 35. 700. ]
[ 35. 725. ]
[ 35. 720. ]
[ 36. 714. ]
[ 36. 850. ]
[ 37. 1000. ]
[ 38.5 920. ]
[ 38.5 955. ]
[ 39.5 925. ]
[ 41. 975. ]
[ 41. 950. ]
[ 9.8 6.7]
[ 10.5 7.5]
[ 10.6 7. ]
[ 11. 9.7]
[ 11.2 9.8]
[ 11.3 8.7]
[ 11.8 10. ]
[ 11.8 9.9]
[ 12. 9.8]
[ 12.2 12.2]
[ 12.4 13.4]
[ 13. 12.2]
[ 14.3 19.7]
[ 15. 19.9]]
샘플, 특성 수 출력
print(input_arr.shape)
# (49, 2)
arrange()로 인덱스 랜덤 섞기
seed로 고정
np.random.seed(42)
index = np.arange(49)
np.random.shuffle(index)
print(index)
# [13 45 47 44 17 27 26 25 31 19 12 4 34 8 3 6 40 41 46 15 9 16 24 33
# 30 0 43 32 5 29 11 36 1 21 2 37 35 23 39 10 22 18 48 20 7 42 14 28
# 38]
배열 인덱싱
인덱스 여러개로 한번에 여러개 원소 선택
print(input_arr[[1,3]])
# [[ 26.3 290. ]
# [ 29. 363. ]]
훈련 세트 만들기
train_input = input_arr[index[:35]]
train_target = target_arr[index[:35]]print(input_arr[13], train_input[0])
# [ 32. 340.] [ 32. 340.]
테스트 세트 만들기
test_input = input_arr[index[35:]]
test_target = target_arr[index[35:]]
산점도로 데이터 확인
import matplotlib.pyplot as plt
plt.scatter(train_input[:, 0], train_input[:, 1])
plt.scatter(test_input[:, 0], test_input[:, 1])
plt.xlabel('length')
plt.ylabel('weight')
plt.show()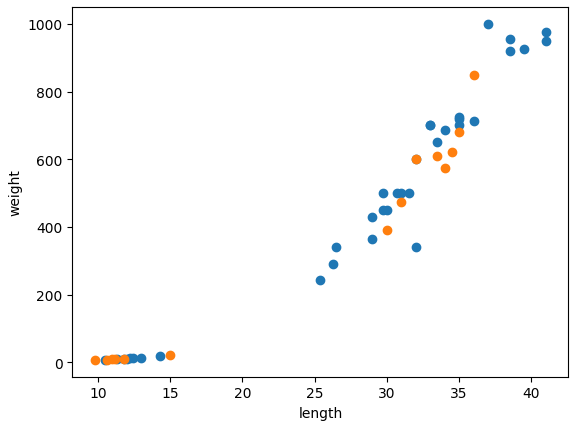
k-최근접 이웃 모델 훈련 / 머신러닝 프로그램2
kn.fit(train_input, train_target)
kn.score(test_input, test_target)
# 1.0kn.predict(test_input)
# array([0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1, 0])test_target
# array([0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1, 0])
넘파이로 데이터 준비
fish_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0, 9.8,
10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
fish_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0, 6.7,
7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]import numpy as np
튜플로 전달(수정 불가)
np.column_stack(([1,2,3], [4,5,6]))
# array([[1, 4],
# [2, 5],
# [3, 6]])
길이, 무게 통합
fish_data = np.column_stack((fish_length, fish_weight))print(fish_data[:5])
# [[ 25.4 242. ]
# [ 26.3 290. ]
# [ 26.5 340. ]
# [ 29. 363. ]
# [ 29. 430. ]]print(np.ones(5))
# [1. 1. 1. 1. 1.]
타깃 데이터 만들기(np.concatenate())
fish_target = np.concatenate((np.ones(35), np.zeros(14)))print(fish_target)
# [1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.
# 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
# 0.]
사이킷런으로 훈련 세트와 테스트 세트 나누기
from sklearn.model_selection import train_test_split
랜덤 시드 42 지정
25%를 테스트 세트로
train_input, test_input, train_target, test_target = train_test_split(
fish_data, fish_target, random_state=42)print(train_input.shape, test_input.shape)
# (36, 2) (13, 2)
print(train_target.shape, test_target.shape)
# (36,) (13,)
print(test_target)
# [1. 0. 0. 0. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
train_input, test_input, train_target, test_target = train_test_split(
fish_data, fish_target, stratify=fish_target, random_state=42)
print(test_target)
# [0. 0. 1. 0. 1. 0. 1. 1. 1. 1. 1. 1. 1.]
k-최근접 이웃 훈련
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()
kn.fit(train_input, train_target)
kn.score(test_input, test_target)
# 1.0
도미를 방어로 잘못 예측
print(kn.predict([[25, 150]]))
# [0.]import matplotlib.pyplot as plt
plt.scatter(train_input[:,0], train_input[:,1])
plt.scatter(25, 150, marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
distances, indexes = kn.kneighbors([[25, 150]])
훈련 데이터 중이웃 샘플 따로 구분
plt.scatter(train_input[:,0], train_input[:,1])
plt.scatter(25, 150, marker='^')
plt.scatter(train_input[indexes,0], train_input[indexes,1], marker='D')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
print(train_input[indexes])
# [[[ 25.4 242. ]
# [ 15. 19.9]
# [ 14.3 19.7]
# [ 13. 12.2]
# [ 12.2 12.2]]]print(train_target[indexes])
[[1. 0. 0. 0. 0.]]print(distances)
# [[ 92.00086956 130.48375378 130.73859415 138.32150953 138.39320793]]
xlim()으로 x축 범위 지정
plt.scatter(train_input[:,0], train_input[:,1])
plt.scatter(25, 150, marker='^')
plt.scatter(train_input[indexes,0], train_input[indexes,1], marker='D')
plt.xlim((0, 1000))
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
두 특성의 값이 놓인 범위가 매우 다름
ㄴ스케일이 다름
데이터 전처리
특성값을 일정한 기준으로
ㄴ 표준점수(z점수): 각 특성값이 평균에서 표준편차의 몇 배만큼 떨어져 있는지 나타냄
mean = np.mean(train_input, axis=0)
std = np.std(train_input, axis=0)
print(mean, std)
# [ 27.29722222 454.09722222] [ 9.98244253 323.29893931]
표준점수 변환
ㄴ넘파이 기능 브로드캐스팅(넘파이 배열 사이에서 일어남[train_input, mean, std])
train_scaled = (train_input - mean) / std
전처리 데이터로 모델 훈련
plt.scatter(train_scaled[:,0], train_scaled[:,1])
plt.scatter(25, 150, marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
샘플을 동일한 비율로 변환
new = ([25, 150] - mean) / std
plt.scatter(train_scaled[:,0], train_scaled[:,1])
plt.scatter(new[0], new[1], marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
k-최근접 이웃 모델 다시 훈련
kn.fit(train_scaled, train_target)
test_scaled = (test_input - mean) / std
모델 평가
kn.score(test_scaled, test_target)
# 1.0
도미 다시 예측
print(kn.predict([new]))
# [1.]
결과 시각화: 특성값의 스케일에 민감하지 않고 안정적인 예측
distances, indexes = kn.kneighbors([new])
plt.scatter(train_scaled[:,0], train_scaled[:,1])
plt.scatter(new[0], new[1], marker='^')
plt.scatter(train_scaled[indexes,0], train_scaled[indexes,1], marker='D')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()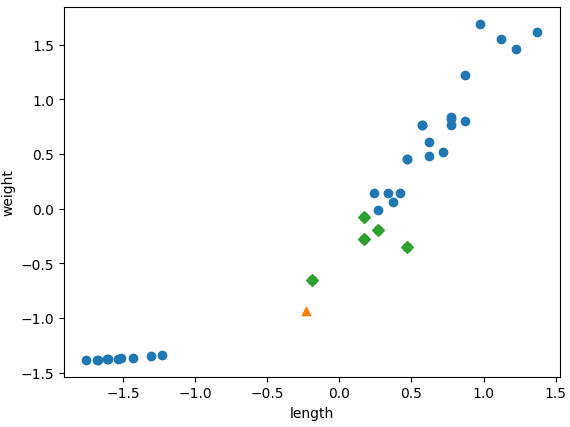
k-최근접 이웃 회귀
지도
분류와 회귀로 나뉨
회귀: 클래스 중 하나로 분류하는 것이 아니라 임의의 어떤 숫자를 예측하는 문제
ㄴ두 변수 사이의 상관관계 분석하는 방법
import numpy as npperch_length = np.array(
[8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0,
21.0, 21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5,
22.5, 22.7, 23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5,
27.3, 27.5, 27.5, 27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0,
36.5, 36.0, 37.0, 37.0, 39.0, 39.0, 39.0, 40.0, 40.0, 40.0,
40.0, 42.0, 43.0, 43.0, 43.5, 44.0]
)
perch_weight = np.array(
[5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0,
110.0, 115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0,
130.0, 150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0,
197.0, 218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0,
514.0, 556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0,
820.0, 850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0,
1000.0, 1000.0]
)import matplotlib.pyplot as pltplt.scatter(perch_length, perch_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
from sklearn.model_selection import train_test_splittrain_input, test_input, train_target, test_target = train_test_split(
perch_length, perch_weight, random_state=42)test_array = np.array([1,2,3,4])
print(test_array.shape)
# (4,)test_array = test_array.reshape(2, 2)
print(test_array.shape)
# (2, 2)train_input = train_input.reshape(-1, 1)
test_input = test_input.reshape(-1, 1)print(train_input.shape, test_input.shape)
# (42, 1) (14, 1)
결정계수(R^2)
회귀 모델이 주어진 데이터에 얼마나 잘 적합(fit) 되는지를 나타내는 통계적 측정치
모델이 종속 변수의 분산 중 얼마나 많은 부분을 독립 변수로 설명할 수 있는지를 0에서 1 사이의 값으로 표현
R(^2) = I - {(타깃 - 예측)^2의 합} / {(타깃 - 평균)^2의 합}
from sklearn.neighbors import KNeighborsRegressorknr = KNeighborsRegressor()
# k-최근접 이웃 회귀 모델 훈련
knr.fit(train_input, train_target)
knr.score(test_input, test_target)
# 0.992809406101064from sklearn.metrics import mean_absolute_error# 테스트 세트에 대한 예측 생성
test_prediction = knr.predict(test_input)
# 테스트 세트에 대한 평균 절댓값 오차 계산
mae = mean_absolute_error(test_target, test_prediction)
print(mae)
# 19.157142857142862
과대적합
훈련 세트에서 점수가 좋았으나 테스트 세트에서 점수가 굉장히 나쁠 경우 모델이 훈련 세트에 과대적합
과소적합
반대로 훈련 세트보다 테스트 세트 점수가 높거나 두 점수가 모두 너무 낮은 경우
print(knr.score(train_input, train_target))
# 0.9698823289099254# 이웃의 갯수를 3으로 설정
knr.n_neighbors = 3
# 모델을 다시 훈련
knr.fit(train_input, train_target)
print(knr.score(train_input, train_target))
# 0.9804899950518966print(knr.score(test_input, test_target))
# 0.9746459963987609
선형 회귀
k-최근접 이웃의 한계
import numpy as np
perch_length = np.array(
[8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0,
21.0, 21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5,
22.5, 22.7, 23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5,
27.3, 27.5, 27.5, 27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0,
36.5, 36.0, 37.0, 37.0, 39.0, 39.0, 39.0, 40.0, 40.0, 40.0,
40.0, 42.0, 43.0, 43.0, 43.5, 44.0]
)
perch_weight = np.array(
[5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0,
110.0, 115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0,
130.0, 150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0,
197.0, 218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0,
514.0, 556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0,
820.0, 850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0,
1000.0, 1000.0]
)
from sklearn.model_selection import train_test_split
# 훈련 세트와 테스트 세트로 분리
train_input, test_input, train_target, test_target = train_test_split(
perch_length, perch_weight, random_state=42)
# 훈련 세트와 테스트 세트를 2차원 배열로 변경
train_input = train_input.reshape(-1, 1)
test_input = test_input.reshape(-1, 1)
from sklearn.neighbors import KNeighborsRegressor
knr = KNeighborsRegressor(n_neighbors=3)
# k-최근접 이웃 회귀 모델 훈련
knr.fit(train_input, train_target)
print(knr.predict([[50]]))
# [1033.33333333]import matplotlib.pyplot as plt
# 50cm 농어의 이웃을 구함
distances, indexes = knr.kneighbors([[50]])
# 훈련 세트의 산점도
plt.scatter(train_input, train_target)
# 훈련 세트 중에서 이웃 샘플만 다시 그림
plt.scatter(train_input[indexes], train_target[indexes], marker='D')
# 50cm 농어 데이터
plt.scatter(50, 1033, marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
print(np.mean(train_target[indexes]))
# 1033.3333333333333
print(knr.predict([[100]]))
# [1033.33333333]# 100cm 농어의 이웃을 구함
distances, indexes = knr.kneighbors([[100]])
# 훈련 세트의 산점도
plt.scatter(train_input, train_target)
# 훈련 세트 중에서 이웃 샘플만 다시 그림
plt.scatter(train_input[indexes], train_target[indexes], marker='D')
# 100cm 농어 데이터
plt.scatter(100, 1033, marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()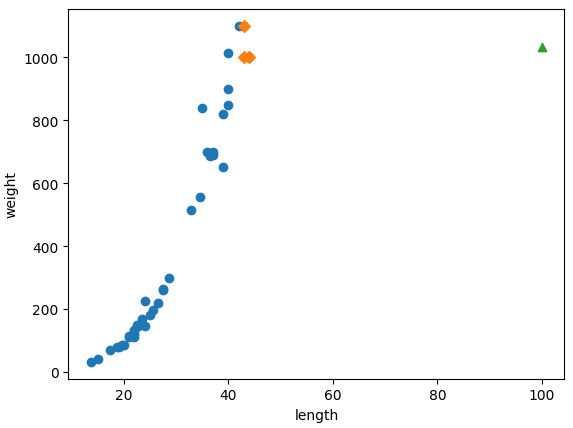
선형 회귀
특성이 하나인 경우 어떤 직선을 학습하는 알고리즘
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
# 선형 회귀 모델 훈련
lr.fit(train_input, train_target)

# 50cm 농어에 대한 예측
print(lr.predict([[50]]))
# [1241.83860323]
print(lr.coef_, lr.intercept_)
# [39.01714496] -709.0186449535477# 훈련 세트의 산점도
plt.scatter(train_input, train_target)
# 15에서 50까지 1차 방정식 그래프
plt.plot([15, 50], [15*lr.coef_+lr.intercept_, 50*lr.coef_+lr.intercept_])
# 50cm 농어 데이터
plt.scatter(50, 1241.8, marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
print(lr.score(train_input, train_target))
print(lr.score(test_input, test_target))
# 0.939846333997604
# 0.8247503123313558
다항 회귀
독립 변수와 종속 변수 간의 관계를 1차 함수(직선)가 아닌 다항 함수(곡선)를 사용하여 모델링하는 회귀 분석 방법
train_poly = np.column_stack((train_input ** 2, train_input))
test_poly = np.column_stack((test_input ** 2, test_input))
print(train_poly.shape, test_poly.shape)
# (42, 2) (14, 2)
lr = LinearRegression()
lr.fit(train_poly, train_target)
print(lr.predict([[50**2, 50]]))
# [1573.98423528]
print(lr.coef_, lr.intercept_)
# [ 1.01433211 -21.55792498] 116.0502107827827# 구간별 직선을 그리기 위해 15에서 49까지 정수 배열 생성
point = np.arange(15, 50)
# 훈련 세트의 산점도
plt.scatter(train_input, train_target)
# 15에서 49까지 2차 방정식 그래프를 그림
plt.plot(point, 1.01*point**2 - 21.6*point + 116.05)
# 50cm 농어 데이터
plt.scatter([50], [1574], marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
print(lr.score(train_poly, train_target))
print(lr.score(test_poly, test_target))
# 0.9706807451768623
# 0.9775935108325122
다중 회귀
여러개의 특성을 사용한 선형 회귀
특성 공학
기존의 특성을 사용해 새로운 특성을 뽑아내는 작업
판다스
데이터 분석 라이브러리
데이터프레임
판다스의 핵시 뎅이터 구조
import pandas as pd
df = pd.read_csv('https://bit.ly/perch_csv_data')
perch_full = df.to_numpy()
print(perch_full)[[ 8.4 2.11 1.41]
[13.7 3.53 2. ]
[15. 3.82 2.43]
[16.2 4.59 2.63]
[17.4 4.59 2.94]
[18. 5.22 3.32]
[18.7 5.2 3.12]
[19. 5.64 3.05]
[19.6 5.14 3.04]
[20. 5.08 2.77]
[21. 5.69 3.56]
[21. 5.92 3.31]
[21. 5.69 3.67]
[21.3 6.38 3.53]
[22. 6.11 3.41]
[22. 5.64 3.52]
[22. 6.11 3.52]
[22. 5.88 3.52]
[22. 5.52 4. ]
[22.5 5.86 3.62]
[22.5 6.79 3.62]
[22.7 5.95 3.63]
[23. 5.22 3.63]
[23.5 6.28 3.72]
[24. 7.29 3.72]
[24. 6.38 3.82]
[24.6 6.73 4.17]
[25. 6.44 3.68]
[25.6 6.56 4.24]
[26.5 7.17 4.14]
[27.3 8.32 5.14]
[27.5 7.17 4.34]
[27.5 7.05 4.34]
[27.5 7.28 4.57]
[28. 7.82 4.2 ]
[28.7 7.59 4.64]
[30. 7.62 4.77]
[32.8 10.03 6.02]
[34.5 10.26 6.39]
[35. 11.49 7.8 ]
[36.5 10.88 6.86]
[36. 10.61 6.74]
[37. 10.84 6.26]
[37. 10.57 6.37]
[39. 11.14 7.49]
[39. 11.14 6. ]
[39. 12.43 7.35]
[40. 11.93 7.11]
[40. 11.73 7.22]
[40. 12.38 7.46]
[40. 11.14 6.63]
[42. 12.8 6.87]
[43. 11.93 7.28]
[43. 12.51 7.42]
[43.5 12.6 8.14]
[44. 12.49 7.6 ]]import numpy as np
perch_weight = np.array(
[5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0,
110.0, 115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0,
130.0, 150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0,
197.0, 218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0,
514.0, 556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0,
820.0, 850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0,
1000.0, 1000.0]
)
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(perch_full, perch_weight, random_state=42)
사이킷런의 변환기
특성을 만들거나 전처리하는 클래스
타깃 데이터 없이 입력 데이터를 변환
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures()
poly.fit([[2, 3]])
print(poly.transform([[2, 3]]))
# [[1. 2. 3. 4. 6. 9.]]
poly = PolynomialFeatures(include_bias=False)
poly.fit([[2, 3]])
print(poly.transform([[2, 3]]))
# [[2. 3. 4. 6. 9.]]
poly = PolynomialFeatures(include_bias=False)
poly.fit(train_input)
train_poly = poly.transform(train_input)
print(train_poly.shape)
# (42, 9)
poly.get_feature_names_out()
# array(['x0', 'x1', 'x2', 'x0^2', 'x0 x1', 'x0 x2', 'x1^2', 'x1 x2',
# 'x2^2'], dtype=object)
test_poly = poly.transform(test_input)
다중 회귀 모델 훈련하기
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(train_poly, train_target)
print(lr.score(train_poly, train_target))
# 0.9903183436982125
print(lr.score(test_poly, test_target))
# 0.9714559911594111
poly = PolynomialFeatures(degree=5, include_bias=False)
poly.fit(train_input)
train_poly = poly.transform(train_input)
test_poly = poly.transform(test_input)
print(train_poly.shape)
# (42, 55)
lr.fit(train_poly, train_target)
print(lr.score(train_poly, train_target))
# 0.9999999999996433
print(lr.score(test_poly, test_target))
# -144.40579436844948
규제
머신러닝 모델이 훈련 세트를 너무 과도하게 학습하지 못하도록 훼방하는
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_poly)
train_scaled = ss.transform(train_poly)
test_scaled = ss.transform(test_poly)
릿지 회귀
기존 선형 회귀 모델에 L2 규제(Regularization)를 추가한 방법
모델의 가중치(회귀 계수)가 너무 커지는 것을 방지하여 과대적합(Overfitting)을 줄이는 데 사용
from sklearn.linear_model import Ridge
ridge = Ridge()
ridge.fit(train_scaled, train_target)
print(ridge.score(train_scaled, train_target))
# 0.9896101671037343
print(ridge.score(test_scaled, test_target))
# 0.9790693977615387
import matplotlib.pyplot as plt
train_score = []
test_score = []
alpha_list = [0.001, 0.01, 0.1, 1, 10, 100]
for alpha in alpha_list:
# 릿지 모델 생성
ridge = Ridge(alpha=alpha)
# 릿지 모델 훈련
ridge.fit(train_scaled, train_target)
# 훈련 점수와 테스트 점수 저장
train_score.append(ridge.score(train_scaled, train_target))
test_score.append(ridge.score(test_scaled, test_target))
plt.plot(np.log10(alpha_list), train_score)
plt.plot(np.log10(alpha_list), test_score)
plt.xlabel('alpha')
plt.ylabel('R^2')
plt.show()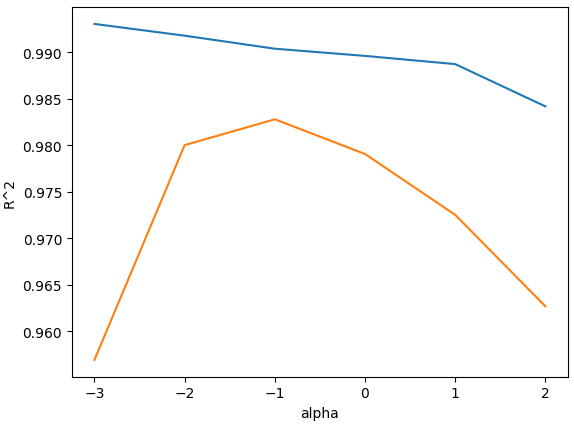
ridge = Ridge(alpha=0.1)
ridge.fit(train_scaled, train_target)
print(ridge.score(train_scaled, train_target))
print(ridge.score(test_scaled, test_target))
# 0.9903815817570367
# 0.9827976465386928
라쏘 회귀
기존 선형 회귀 모델에 L1 규제(Regularization)를 추가한 방법
릿지 회귀와 마찬가지로 과대적합을 방지하는 목적을 가지며, 모델의 복잡도를 줄이는 데 기여
from sklearn.linear_model import Lasso
lasso = Lasso()
lasso.fit(train_scaled, train_target)
print(lasso.score(train_scaled, train_target))
# 0.989789897208096
print(lasso.score(test_scaled, test_target))
# 0.9800593698421883
train_score = []
test_score = []
alpha_list = [0.001, 0.01, 0.1, 1, 10, 100]
for alpha in alpha_list:
# 라쏘 모델 생성
lasso = Lasso(alpha=alpha, max_iter=10000)
# 라쏘 모델 훈련
lasso.fit(train_scaled, train_target)
# 훈련 점수와 테스트 점수 저장
train_score.append(lasso.score(train_scaled, train_target))
test_score.append(lasso.score(test_scaled, test_target))
# /usr/local/lib/python3.10/dist-packages/sklearn/linear_model/_coordinate_descent.py:631: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations, check the scale of the features or consider increasing regularisation. Duality gap: 1.878e+04, tolerance: 5.183e+02
# model = cd_fast.enet_coordinate_descent(
# /usr/local/lib/python3.10/dist-packages/sklearn/linear_model/_coordinate_descent.py:631: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations, check the scale of the features or consider increasing regularisation. Duality gap: 1.297e+04, tolerance: 5.183e+02
# model = cd_fast.enet_coordinate_descent(
plt.plot(np.log10(alpha_list), train_score)
plt.plot(np.log10(alpha_list), test_score)
plt.xlabel('alpha')
plt.ylabel('R^2')
plt.show()
lasso = Lasso(alpha=10)
lasso.fit(train_scaled, train_target)
print(lasso.score(train_scaled, train_target))
print(lasso.score(test_scaled, test_target))
# 0.9888067471131867
# 0.9824470598706695
print(np.sum(lasso.coef_ == 0))
# 40
'로보테크AI' 카테고리의 다른 글
| 융합_로보테크 AI 자율주행 로봇 개발자 과정-26/03/20 (0) | 2026.03.20 |
|---|---|
| 융합_로보테크 AI 자율주행 로봇 개발자 과정-26/03/19 (0) | 2026.03.19 |
| 융합_로보테크 AI 자율주행 로봇 개발자 과정-26/03/17 (0) | 2026.03.17 |
| 융합_로보테크 AI 자율주행 로봇 개발자 과정-26/03/16[트위니 특강] (0) | 2026.03.16 |
| 융합_로보테크 AI 자율주행 로봇 개발자 과정-26/03/13 +자소서 특강 (0) | 2026.03.13 |